谈谈银行核心系统建设--篇5:核心系统的批量处理
文章来源:e路向上,文章仅供个人学习
银行系统的批量处理对业务人员而言相对陌生,但对很多技术(主要是开发)人员却是梦魇一般的存在。对有批处理作业的系统来说,开发人员在午夜接到操作员的电话,大概就跟听到午夜凶铃差不多。笔者当年刚毕业时的岗位导师,经常三更半夜跑回机房处理系统批量问题的情景,时至今日,仍历历在目。他每每一到现场就能手到擒来解决掉问题的卓越技术能力,不管什么时间,电话响过后总能第一时间出现在现场(当年那个时候还没有VPN之类的)的敬业精神,给刚踏入职场的笔者上了最好的一课。见贤思齐,批处理工作留下的痕迹,在笔者身上也以生物钟的方式留下了深深的刻痕:23:00前一般不会睡觉–因为当年团队的商业汇票系统到这个点批处理还没报错才算安稳;凌晨3:00准时醒来一次–因为当年的信贷批量这个点差不多跑完,要瞅瞅有没有批量告警短信..
那么,银行系统的批量处理到底是什么,它为什么这么重要,是什么让赚着卖白菜钱的程序猿们,不得不操作卖白粉的心,有没有什么办法让开发人员不再对批处理谈虎色变、让这一切更从容不迫,优雅淡定呢?本篇试着做些抛砖引玉的讨论…
银行系统为什么会有“批量****”处理
对从互联网转行到银行业的开发人员而言,系统批量处理的概念是很不好理解的,这不就是一堆Timer Tasks吗,为啥到了银行就变成了Batch Processing了?回顾历史不是为了固步自封,而是为了知道我们曾经从哪里出发,以及为了什么而出发…
我们先把视线拉回到银行业刀耕火种的手工时代,银行柜面的“账房”们,日间在柜台受理客户的各种交易请求,做好两方面的工作:编制交易传票(填写凭证)以及登记分户账/台账。在忙完一天的工作打烊后–这并不意味着一天的工作结束,除了要检查、对平现金尾箱、重要凭证库(这个工作在今天的银行网点仍在继续)外,留给他们的,还有很重要的几项工作:根据分户登记科目日结单,登记总账,及填写科目日计表:在第二天开业前,把头一天的账务记个清楚明白。
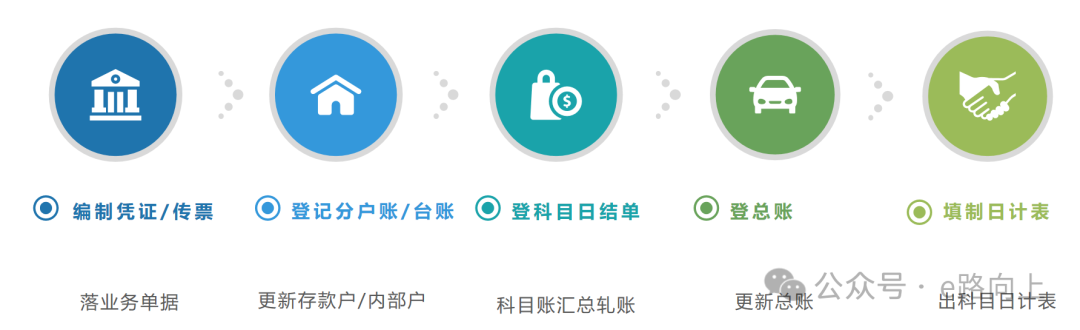
这一处理,被延续到会计电算化时代,再到银行业的全面信息化时代…这应该是银行系统批处理的第一推动:科目账需要根据营业日分户账的情况在营业结束后进行更新,以编制动态变化的银行资产负债表与利润表。顺带说一句:目前计算机系统对账务的处理基本模拟手工账处理的流程,处理账务的工具和能力变了,但本质的业务思想并没有变。
除科目账的更新外,另外还有一项在批处理中非常重要的工作–“计提”(它还有个对应的概念是“摊销”,都是会计概念),原因是根据现代会计的权责发生制原则,损益的确认不能等到收付实现的那一刻(看起来费劲的开发同学,未来又有志于在银行IT行业发展的,建议自学一下银行会计)。因此,对每一笔存款和每一笔贷款,当然还有银行持有的各种固收类资产(比如债券、贴入的商票等),每天都要计算这笔负债或者资产当天带来的利息支出或收入。在计算机系统被全面应用于银行业务处理之前,依靠会计人员手工处理的方式,是不可想象的(比如某个网点有1万个存款户,要每天靠人手工算一遍应该给多少利息(且不论计提与实付间出现差额需要回冲或补记的情形…),而在银行业务信息化后,每天分别计算负债业务的利息支出及资产业务的利息收入,就成为银行财务管理的基本要求。这种计提处理,并非客户主动发起的业务请求,而是银行为满足内部管理要求,由计算机系统自动完成、按批量化模式来进行整体处理的作业,与一笔一笔的业务相比,这是批量化的…
基于交易明细完成当天的总账账务处理以及对明细的资产负债项目按权责发生制原则进行计提处理,即是银行系统批量处理的最初起源,看起来都是起源于会计的需要。
核心系统的批处理过程中还会做什么
有读者应该会马上提出疑问,你这漏了好多东西,我们银行系统的批处理内容比这多多了。没错,上一部分提到的批处理,只是批处理的关键核心任务。实际上,核心系统在横向的任务类型和纵向的前后置作业上,都还有很多内容:
其他常见包含的任务。在很多商业银行,这么几类作业很多时候也会纳入批处理作业范畴。1、设定有期限,到期由系统自动化处理的任务,会被纳入批处理的任务清单中,比如:挂失业务的到期解挂、账户冻结的到期解冻、定期存单的到期自动转存等;2、按管理规定要求,需要执行的账户状态设置。比如结算户自动转不动户、转久悬户,直至自动销户的处理,贷款逾期90天后,转非应计状态的处理等;3、费用的收取或摊销。比如有些银行将小额账户管理费,也放在核心系统批处理阶段进行计算,预收费用的摊销处理;4、结息处理;5、账户利率变更…等等。这些任务的特点是,都不是客户主动发起的,而是依据客户服务合约,或银行自身的经营政策、管理要求,对所有业务记录进行的统一处理。
批处理的序时处理。为进行批量处理,在系统中引入了一个“会计日”(account date)概念,这一日期用于记录一笔涉账类交易入账时的账务日期,批处理中的切日,实际上说的是切换这个“会计日”(而非自然日,自然日用不着我们画蛇添足)。举例解释一下:系统要为一个账户计算利息,需要有个基准的计息余额,假设某银行将核心的切日时间设定为每天的23:00点,则在23:00后,账户发生的存入和支取金额,则不会被用于计息(当然,没有绝对,看系统怎么设计),而是反应在下一天。同样的,这个存款账户对应的存款科目账,在加工当日总账的时候,也不会被计入,而是计入为下一天,因为会计分录信息中的那个会计日,填写的就是T+1日。以营业日切换为分界线,批处理实际上在大的粒度上被切分为这样一个结构:
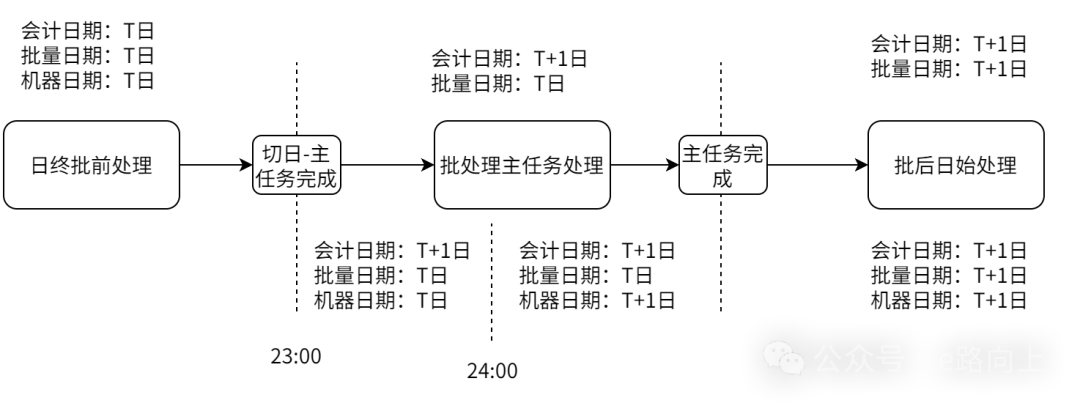
上图假设某银行设定的日切时点是23:00,系统设计上引入了批量日期的概念。在这样一个序时处理过程中:
日终批前处理任务。是指为保证T日的任务能在切换会计日前得到处理而进行作业,通常以某种定时任务方式进行处理。比如有笔T日到期的贷款需要扣款,则需要在切日前再进行一次批扣;又比如通过存贷联动完成的法透放款,为保证贷款和存款之间的账务一致性,也需要在日切前,完成放款处理。
批处理主任务。真正最关键的,就是计提,以及各分户账系统生成的当日总分核对账务文件,还有会计引擎(如有)根据T日日间生成的会计分录明细,加工的总账借贷方发生额明细及汇总文件,用于更新总账。同时一般还会伴随将T日的各类数据,以快照档案的方式,下送数据仓库。
批后日始处理任务。批后日始处理,即在完成日终主任务后,进行的一些处理任务。比较常见的有比如结息,结息需要依赖计提的结果,且在算头不算尾的一般性规则下,结息的处理通常放在核心批量主任务完成后再进行处理;还有贷款的日始批扣,如一笔贷款的还款日是18日,则在18日凌晨某个时点,核心系统完成17日的批处理后,系统即会发起一次处理。其他的还有比如到期解冻、到期自动兑付等等。这里的处理任务,很大一部分,与日终批量前处理一样,是在系统设计上,通过“早 + 晚”的类定时任务(其实日间也可以定义执行类似的执行任务)机制,来保证自动化任务尽可能被成功完成。
回归第一性原理看批量处理的关键路径
在讨论完上述内容后,我们需要回到文章的开头,为什么批处理老是会让程序猿如临大敌呢?不同的银行可能有不同的原因,但一般来说,很多银行会将总账完成T日的科目账更新(即T日的日计表已全部生成)作为柜员可签到开始新一天营业的前置,还有些银行会将批处理任务完成所有阶段的任务处理,作为柜员可签到开始新一天营业的前置,在批量任务设计上,还为不同的批处理阶段设置了所谓的模式。
在系统设计上,只有完成某一模式,才能允许柜面签到。因此,批处理的顺利完成,就变得非常重要,因为一旦来到次日9:00还签不了到的话,就可能酿成不能开门营业的重大生产事故(来到这里,数字银行的小伙伴们肯定会觉得匪夷所思,那么多7*24小时的业务在跑着,为什么要单单限制柜面,或者对公业务?是的,这就是传统的惯性),这便是最主要的原因。
另一个原因则来自于各类下游数据处理的要求,比如要按时报送监管报表,比如要产出给银行管理层看的各类报表,他们都需要依赖业务系统在完成T日的所有处理后(包括业务数据和账务数据的处理),将T日的业务数据和账务数据下送给数据仓库,并形成当日的数据快照,以继续下一步的后续处理,除月末、季末之类的特殊时点外,多数时候对外报送数据的时效要求并不高,压力的来源主要是管理层,每天各种关键业务指标,是不是如期摆在了行领导们的办公桌上,如果没有,且是因为技术原因导致的,技术团队每每都会如临大敌–记住“Boss Requirement”永远优先于 “Business Requiement”的铁律 :)。
从以上关键影响可以看出,真正构成关键依赖的,实际上是T日的交易类账务、T日批处理过程中发生账务处理(其中主要是计提),以及分户数据和总账数据的入仓。其中,对建设有会计引擎的银行而言,T日的交易类账务,在交易过程中已经通过准实时消息的方式,进入了会计引擎,而会计引擎及总账的加工,本身与开门营业并没有任何的必然联系,而分户数据的下档,在会计日切换的那一刻,除了后续要发生计提影响分户的应收付利息,以及进行利率调整时需要进行记录利率调整信息外,剩下的所有数据,在当时的时点均可形成快照,也即意味着:如果数据模型设计合理,很多分户数据甚至不用等待批处理,即可下送数仓。因此,批处理任务中,关键的关键,便聚焦到一点:以最高的效率,完成一般商业银行笔数占比最高的几类业务的计提及相关处理,他们包括:个人活期存款、个人定期存款、个人贷款。
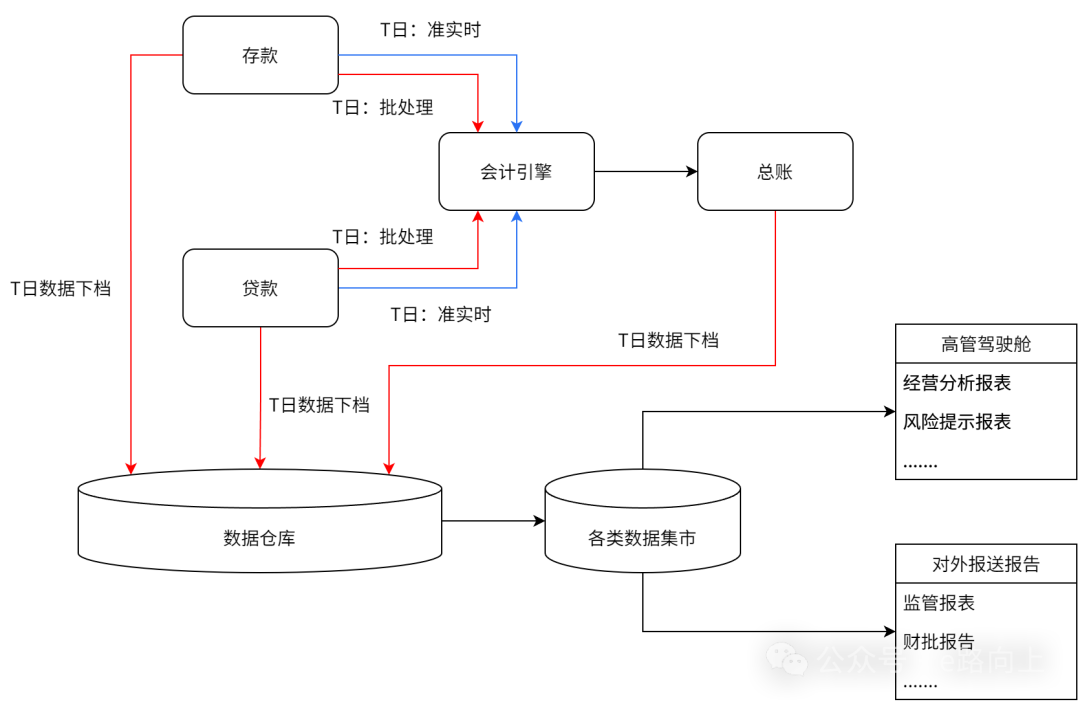
核心建设项目中怎么定义批量的需求
基于上述讨论,很显然地,在核心系统的项目建设中,批处理也是需要关注的重要内容之一,而最后这个东西会做成怎么样,其实跟一开始的要求–即需求定义息息相关。对核心系统的批处理而言,定义批量处理的需求,建议特别关注以下几点:
一是业务功能类的需求。这个是最不容易忽视的,主要是比如贷款批扣还款、定期到期续存或转回、冻结的到期解冻、挂失的到期解挂等等,在什么时点,以什么方式发生,业务需要跟踪的处理结果以什么方式呈现给业务人员;计提的计息方式、结息频率、结息成功与否等等,不作赘述;
二是更关键的技术指标定义。即在项目建设初期,要设定性能与效率指标,基于所在行的业务体量,你准备用多少时间完成批处理的关键路径,要在需求定义阶段进行明确,以为后续在设计方案中进行考虑,这点非常非常关键,且很多时候容易被忽略;
三是运维与容错类的需求。这个既可以说是需求,其实更多是方案,比如是不是允许批处理过程中,出错后先将错误抛出,等上班了再做事后处理,或者批量过程中某条记录出错,是否允许自动跳过,继续执行其他的处理。如果有非处理不可的错误,修复后是否允许重跑,重跑时需要控制已经处理过的任务不被重复执行。这条内容对系统进入运维阶段后,负责核心批量的同事能不能睡个好觉至关重要–这里面每条都可以做到,其实很多时候,报错根本没什么大不了的,关键是不要有类似这种愚蠢的设计:“一条记录跑不下去,整个作业都被Pending”。
四是厘清依赖关系。账户、内部户、会计引擎等作为中枢类的系统,当发生存抵贷、法人账户透支、贷款转让、组合计息、贷款还款等等需要系统间交互的处理时,系统间的依赖与约束,需要在产品需求中进行定义;
五是确定切日的时间点。日切时间点当然是与机器日期越接近越好,即00:00进行日切,就一般不需要在给客户的日结单上弄出来一个交易日期后,再弄个营业日期(或者会计日期,或者其他的什么名称)。但有些机构考虑到处理问题的需要,有的会选择22:00,也有的会是23:00等等,但不论几点,一定要先定义好,因为外面还有一堆的系统,需要根据核心的切日时间,对自己的处理进行调整。
六是定义724小时类系统的范围。最简单的仍然是核心这一逻辑概念下的子系统,全都支持724小时,相关的其实主要是几个账务系统(假定贷款不在核心范畴内):个人活期存款、个人定期存款、对公活期、对公定期、保证金、内部户、存放同业等等。但实际上,因为银行业务的特殊性,比如对公业务一般假日以及下班后是不营业的,所以很多时候会不需要支持724小时。不过,在技术同源的情况下,最好是这些带账系统,都支持724小时,比如企业业务,如果企业有夜间的贵金属、美股投资之类的需求呢?但不论如何,这些都应该在需求阶段说清楚。
上述这些需求中,二、三是与业务关系不大的,但跟对应开发人员的幸福息息相关,作为系统的建设者,更应该特别关注。
批量处理的技术方案
在比较早期的IBM大型机时代,批量处理要解决的技术问题其实是由两个关键问题构成的,一是因为采用VSAM文件的原因,怎么实现724小时的处理;二是怎么解决批量处理的效率问题。在IBM VSAM文件时代,批处理通过所谓双主档拷贝模式,来实现对724小时的支持,简单示意如下:
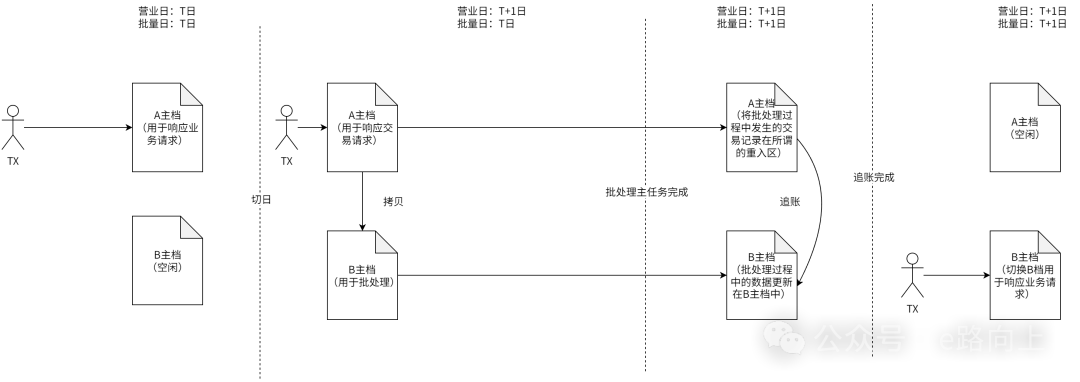
其处理效率强大能力之一来自于IBM大型机为I/O所做的专门优化,而在应用侧,则把所有能做的事情,全都怼在批量主任务的流程中进行处理,甚至包括出具各类报表,于是在目前仍使用MF的银行,时常会见到zzzzzz,999999这样表示的报表,这基本上略等于因为手上拿着倚天剑,即便不会什么武功,也一样可以打遍天下。
进入开放式核心时代后,数据层绝大部分被替换为在小型机上运行的Oracle,得益于数据库本身的ACID机制,7*24小时处理变得不再复杂(上述IBM时代的双主档拷贝,其实通过上日余额和当前余额的设计,配套交易本身更新余额的一些控制,即能轻松实现)。此外,因为交易与核算的分离(会计引擎:交易与核算分离的前世今生),账务处理的依赖被极大地解耦,早期核心批处理过程中需要从交易日志中提取、补齐会计传票的处理不再成为必需。批处理的关键聚集到处理效率:怎么以最短的时间完成批处理。
简单粗暴低效的办法:游标逐条处理。判断到符合条件的记录后,再完成计提、状态更新等等操作,过程中锁记录,做完一条释放一条,如果银行账户不多,其实未必不可以。这种处理问题很多,比如频繁的fetch操作会导致多次网络往返和数据库I/O,每条记录的提交可能产生事务开销,长事务可能持有锁时间过长,影响并发性能。对账户数不多的中小银行而言(比如香港地区、新加坡的一些地区性银行),这未必不是一种解决方案。但对中国大陆的银行而言,这样一种处理模式基本都不可取。
面向千万级数据量,结合分页加载、多线程及连接池优化等的处理方案。在批处理时,分页加载符合条件的账户记录(加乐观锁),放入内存,将获取的数据按Rowid拆分为多个子任务,利用多线程实现并行处理,再合并批量提交事务–减少I/O交互。对大部分银行而言,纯技术优化的这套组合拳,应该可以有效满足批处理时效性的要求。
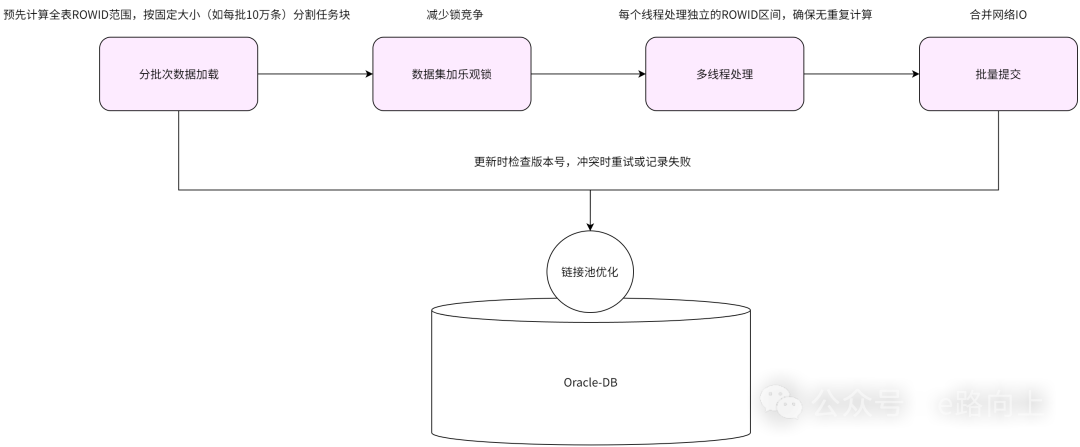
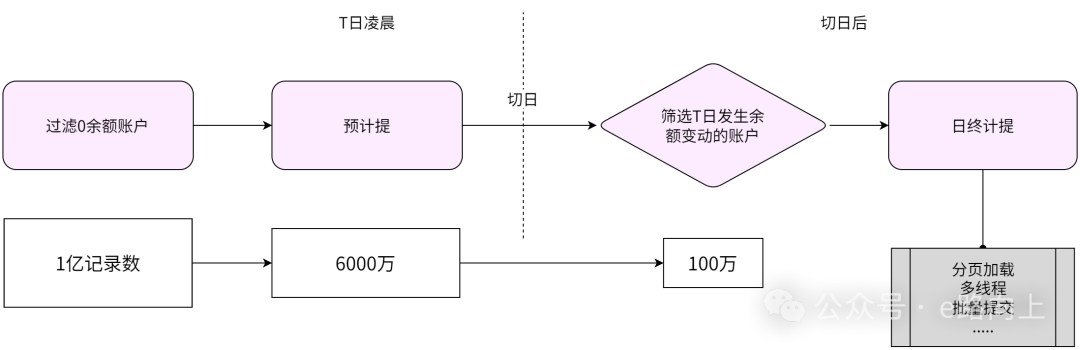
假设银行有上亿的账户,如果还想进一步压缩批处理的时间,还有办法吗?回到业务原理,我们思考两个问题:1)、这上亿的账户里面有多少0余额的僵尸户?2)、这上亿的账户,有多少是一天都没有发生过业务,或者说没有发生过余额变化的?对应的,要进一步压缩批处理的有效时间,方向有两个:一是将需要处理的记录,过滤到最小–比如,0余额的账户,直接都不用做计提处理了,过滤后,要处理的数据集合就大幅减少了;二是拉长战线,有没有可能账户的计提操作,不用等到晚上切日后,再挤在一起进行?答案显然是可以的。于是,优化后的批处理就变成这样:选择交易的低峰时段(比如凌晨2:00~5:00),先对有余额的账户,做一次预计提,然后,在晚上切日后,判断当前余额与预计提时的余额是否发生过变化,如果没有变化,则不需要再做处理,如果有变化,则再计算一次。这样的话,就可以将需要做计提处理的账户记录数,缩小为在当天发生过账务交易的账户上。然后再结合上面的技术方案进行处理,则批处理的时间将被大幅压缩。
如果是几十亿级的账户数呢,更进一步的方案,还可以考虑基于大数据的分布式计算。这一方案中,采用大数据技术栈,支持数据量超10亿的复杂离线计算,但大数据平台回写Oracle时需设计双向校验机制。这一方案中,将计算读和计算的工作交给mpp数据库进行处理,在完成计算后,再对交易库进行回写。
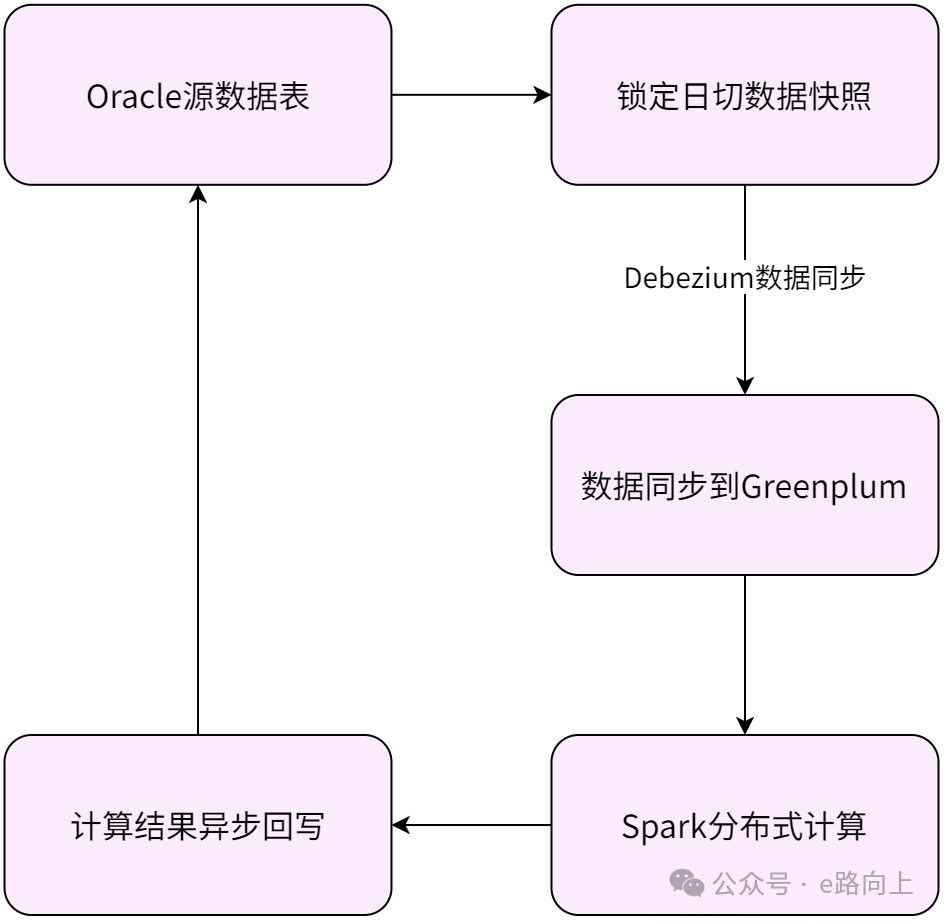
这一方案从根本上脱离了银行核心系统长久以来的批处理思路,相关方案在个别的互联网银行得到运用。从目前商业银行的体量,及批处理本身并没有复杂计算,且需要进行频繁的写操作来看,这一方案在综合ROI上,可能不如上面基于交易库的处理方案,但其开辟的思路,对银行系统设计,仍有相当多的启发。
结语
一篇短短的文章,显然是不可能将复杂的批量处理谈的面面俱到的,要获得真正切身的体感,一方面需要躬身入局,真正去做;另一方面,需要不断地复盘总结,回归到原理去思考和解决问题。当回到最原点后,我们会发现,让开发工程师们苦不堪言的批量处理,其实有很多东西可以解耦,只要采用合理的技术方案,无论是处理效率,还是营业依赖的解耦,都不是什么不可解决的难题。其中关键的关键,还是在于吃透原理,不迷信“向来如此”,敢于在缜密思考的前提下,勇敢地去“打破常规”,这或许也是技术人的进阶之路,共勉。